Copernicus Seasonal Forecast Tools Package: Full Walkthrough
In this notebook, we provide an extended example of the package, including a description of the different configuration options.
This package is developed to manage seasonal forecast data from the Copernicus Climate Data Store (CDS) for the U-CLIMADAPT project. It offers comprehensive tools for downloading, processing, computing climate indices, and generating hazard objects based on seasonal forecast datasets, particularly Seasonal forecast daily and subdaily data on single levels. The package is tailored to integrate seamlessly with the CLIMADA (CLIMate ADAptation) platform, supporting climate risk assessment and the development of effective adaptation strategies.
Features:
Download seasonal forecast data from CDS
Process raw data into climate indices
Calculate various heat-related indices (e.g., Maximum Temperature, Tropical Nights)
Create CLIMADA Hazard objects for further risk analysis
Note: Ensure you have created a CDS account, API credentials, and accepted the dataset’s terms and conditions (see the CDS API setup guide for detailed instructions).
# Import packages
import warnings
import datetime as dt
warnings.filterwarnings('ignore')
from seasonal_forecast_tools import SeasonalForecast
from seasonal_forecast_tools.core.index_definitions import ClimateIndex
from seasonal_forecast_tools.utils.coordinates_utils import (
bounding_box_from_cardinal_bounds,
bounding_box_global,
bounding_box_from_countries,
)
from seasonal_forecast_tools.utils.time_utils import month_name_to_number
Set up parameters
To configure the package for working with Copernicus forecast data and converting it into a hazard object for CLIMADA, you will need to define several essential parameters. These settings are crucial as they specify the type of data to be retrieved, the format, the forecast period, and the geographical area of interest. These parameters influence how the forecast data is processed and transformed into a hazard object.
Below, we outline these parameters and use an example for the “Maximum Temperature” index to demonstrate the seasonal forecast functionality.
To learn more about what these parameters entail and their significance, please refer to the documentation on the CDS webpage.
Overview of parameters
index_metric
Defines the type of index to be calculated. There are currently 12 predefined options available (based on the Thermofeel package), including
Tmean– Mean TemperatureTmin– Minimum TemperatureTmax– Maximum TemperatureHIA– Heat Index AdjustedHIS– Heat Index SimplifiedHUM– HumidexAT– Apparent TemperatureWBGT– Wet Bulb Globe Temperature (Simple)HW– Heat WaveThe optional parameter
thresholdcan be used to define above which temperature days are considered part of a heat wave. Default is 27°C.The optional parameter
min_durationcan be used to define the minimum number of consecutive days above the threshold required to define a heat wave event. Default is 3 days.The optional parameter
max_gapcan be used to define the maximum allowable gap (in days) between two heat wave events to consider them as one single event. Default is 0 days.
TR– Tropical NightsThe optional parameter
thresholdcan be used to define above which temperature a night is considered “tropical.” Default is 20°C.
TX30– Hot Days
Example: Using index_metric = ClimateIndex.Tmax.name selects maximum temperature analysis.
Flexibility: It is possible for users to define and integrate their own indices into the pipeline, according to their specific needs. For this, users must add some code to the code base (at the minimum in the function calculate_heat_indices_metrics of seasonal_forecast_tools/core/seasonal_statistics.py). This can be done in the user’s local clone of the package, or, preferably, it can be added to the package to enhance its usefulness, see the Contribution guide.
format
Specifies the format of the data to be downloaded, "grib" or "netcdf". Copernicus do NOT recommended netcdf format for operational workflows since conversion to netcdf is considered experimental. More information here.
originating_centre
Identifies the source of the data. A standard choice is "dwd" (German Weather Service), one of eight providers including ECMWF, UK Met Office, Météo France, CMCC, NCEP, JMA, and ECCC.
system
Refers to a specific model or configuration used for forecasts. In this script, the default value is "21". which corresponds to the GCSF (German Climate Forecast System) version 2.1. More details can be found in the CDS documentation.
year_list
List of years for data download and processing. Example: year_list = [2022] processes data for 2022.
initiation_month
List of months when forecasts are initiated. Example: initiation_month = ["November"] uses forecasts started in November.
forecast_period
Months for which forecasts are generated, relative to the initiation month. Example: forecast_period = ["December", "February"] forecasts for December through February. The maximum available is 7 months.
Important: When an initiation month is in one year and the forecast period in the next, the system recognizes the forecast extends beyond the initial year. Data is retrieved based on the initiation month, with lead times covering the following year. The forecast is stored under the initiation year’s directory, ensuring consistency while spanning both years.
index_window
Defines the temporal aggregation period for calculating climate indices:
"monthly"(default): Groups data by calendar monthInteger value (e.g.,
15): Creates rolling windows of n consecutive days
Important: This setting determines your final hazard data resolution:
“monthly” → monthly hazard data
15 → 15-day aggregated hazard data
7 → weekly hazard data
Choose your window size based on the temporal scale most relevant to your analysis needs.
area_selection
Defines the geographical area for data download:
Global coverage:
bounds = bounding_box_global()Custom coordinates:
bounds = bounding_box_from_cardinal_bounds(northern=49, eastern=20, southern=40, western=10)(latitude/longitude limits (in EPSG:4326))Country codes:
bounds = bounding_box_from_countries(["URY"])(uses ISO 3166-1 alpha-3 codes). See this wikipedia page for the country codes.
Note that the helper function bounding_box_from_countries is a simple wrapper function around geopandas.GeoSeries.total_bounds.
overwrite
Boolean flag that, when set to True, forces the system to redownload and reprocess existing files.
# We define above parameters for an example
index_metric = ClimateIndex.Tmax.name
data_format = "grib" # 'grib' or 'netcdf'
originating_centre = "dwd"
system = "21"
forecast_period = ["December", "February"] # from December to February including January
year_list = [2022]
initiation_month = ["November"]
overwrite = False
# time frame for calculating index (can be "monthly" or an integer for the number of days)
index_window = "monthly"
# index_window = 15 # every 15 days
# global bounding box
# bounds = bounding_box_global()
# input cardinal bounds
# bounds = bounding_box_from_cardinal_bounds(northern=49, eastern=20, southern=40, western=10)
# input country ISO codes
bounds = bounding_box_from_countries(["URY"])
# Parameters for Heat Waves
hw_threshold = 27
hw_min_duration = 3
hw_max_gap = 0
# Parameters for Tropical Nights
threshold_tr = 20
# Describe the selected climate index and the associated input data
forecast = SeasonalForecast(
index_metric=index_metric,
year_list=year_list,
forecast_period=forecast_period,
initiation_month=initiation_month,
bounds=bounds,
data_format=data_format,
originating_centre=originating_centre,
system=system,
index_window=index_window
)
forecast.explain_index()
'Explanation for Maximum Temperature: Maximum Temperature: Tracks the highest temperature recorded over a specified period. Required variables: 2m_temperature'
Download and Process Data
The forecast.download_and_process_data method in CLIMADA efficiently retrieves and organizes Copernicus forecast data. It checks for existing files to avoid redundant downloads, stores data by format (grib or netCDF), year, month. Then the files are processed for further analysis, such as calculating climate indices or creating hazard objects within CLIMADA. Here are the aspects of this process:
Data Download: The method downloads the forecast data for the selected years, months, and regions. The data is retrieved in grib or netCDF formats, which are commonly used for storing meteorological data. If the required files already exist in the specified directories, the system will skip downloading them, as indicated by the log messages such as:
“Corresponding grib file SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/downloaded_data/grib/TX30_boundsW4_S44_E11_N48.grib already exists.”Data Processing: After downloading (or confirming the existence of) the files, the system converts them into daily netCDF files. Each file contains gridded, multi-ensemble data for daily mean, maximum, and minimum, structured by forecast step, ensemble member, latitude, and longitude. The log messages confirm the existence or creation of these files, for example:
“Daily file SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/processed_data/TX30_boundsW4_S44_E11_N48.nc already exists.”Geographic and Temporal Focus: The files are generated for a specific time frame (e.g., June and July 2022) and a predefined geographic region, as specified by the parameters such as
bounds,month_list, andyear_list. This ensures that only the selected data for your analysis is downloaded and processed.Data Completeness: Messages like “already exists” ensure that you do not redundantly download or process data, saving time and computing resources. However, if the data files are missing, they will be downloaded and processed as necessary.
Note: Exectuing the following line will
download and save raw data from the Copernicus Climate Data Store into the folder downloaded_data/grib/
and then process the data to netcdf format into the folder processed_data/
under
/Users/$USERNAME/climada/data/copernicus_data/seasonal_forecasts/dwd/sys21/2022/init11/valid12_02/.
If needed, the downloaded data can be loaded and analysed directly. See this google colab notebook for some examples.
# Download and process data
forecast.download_and_process_data();
Calculate Climate Indices
When you use the forecast.calculate_index method in CLIMADA to compute specific climate indices (such as Maximum Temperature), the generated output is saved and organized in a structured format for further analysis. Here some details:
Index Calculation: The method processes seasonal forecast data to compute the selected index for the chosen years, months, and regions. This index represents a specific climate condition, such as the number of Maximum Temperature (“Tmax”) over the forecast period, as defined in the parameters.
Data Storage: The calculated index data is saved in netCDF format. These files are automatically saved in directories specific to the index and time period. The file paths are printed below the processing steps. For example, the computed index values are stored in:
Daily Index = daily values of the selected index, saved at “SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/indices/TX30/TX30_boundsW4_S44_E11_N48_daily.nc”.
Index Statistics = similarly, the statistics of the index (e.g., mean, max, min, std) are saved in
“SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/indices/TX30/TX30_boundsW4_S44_E11_N48_stats.nc”.Window Index = mean or count of the index over the defined index_window, saved at “SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/indices/TX30/TX30_boundsW4_S44_E11_N48__index_window_montlhy.nc”.
These files ensure that both the raw indices and their statistical summaries are available for detailed analysis.
Each file contains data for a specific time windows and geographic region, as defined in the parameters. This allows you to analyze how the selected climate index varies over time and across different locations.
Completeness of Data Processing: Messages ‘Index Tmax successfully calculated and saved for…’ confirm the successful calculation and storage of the index, ensuring that all requested data has been processed and saved correctly.
Note:
Exectuing the following line will calculate the requested index and save three files (corresponding to a “daily” file with daily values, a “index_window_monthly” file with the aggregated values for the given index_window – here "monthly" –, and a “stats” file including some statics of the indeces) in the folder indices/Tmax/ under
/Users/$USERNAME/climada/data/copernicus_data/seasonal_forecasts/dwd/sys21/2022/init11/valid12_02/.
Other than further transforming a CLIMADA Hazard object as described below, the index data can be analysed directly. See see this google colab notebook for some examples.
# Calculate index
forecast.calculate_index(hw_threshold=hw_threshold, hw_min_duration=hw_min_duration, hw_max_gap=hw_max_gap);
Calculate a Hazard Object
When you use the forecast.process_and_save_hazards method in CLIMADA to convert processed index from Copernicus forecast data into a hazard object:
Hazard Object Creation: The method processes seasonal forecast data for specified years and index windows (by default months), converting these into hazard objects. These objects encapsulate potential risks associated with specific weather events or conditions, such as Maximum Temperature (‘Tmax’) indicated in the parameters, over the forecast period.
Data Storage: The hazard data for each ensemble member of the forecast is saved as HDF5 files. These files are automatically stored in specific directories corresponding to the index window and type of hazard. The file paths are printed below the processing steps. For example, “/SYSTEM_DIR/copernicus_data/seasonal_forecasts/dwd/sys21/2023/init03/valid06_08/hazard/TX30/TX30_boundsW4_S44_E11_N48_index_window_monthly.hdf5”. HDF5 is a versatile data model that efficiently stores large volumes of complex data.
Each file is specific to a particular month and hazard scenario (‘Tmax’ in this case) and covers all ensemble members for that forecast period, aiding in detailed risk analysis.
Completeness of Data Processing: Messages like ‘Completed processing for 2022-07. Data saved in…’ confirm the successful processing and storage of the hazard data for that period, ensuring that all requested data has been properly handled and stored.
Note: Exectuing the following line will transform the computed index values to a CLIMADA Hazard object and save the result in the folder hazard/Tmax/ under
/Users/$USERNAME/climada/data/copernicus_data/seasonal_forecasts/dwd/sys21/2022/init11/valid12_02/,
forecast.save_index_to_hazard();
Example for reading and plotting hazard
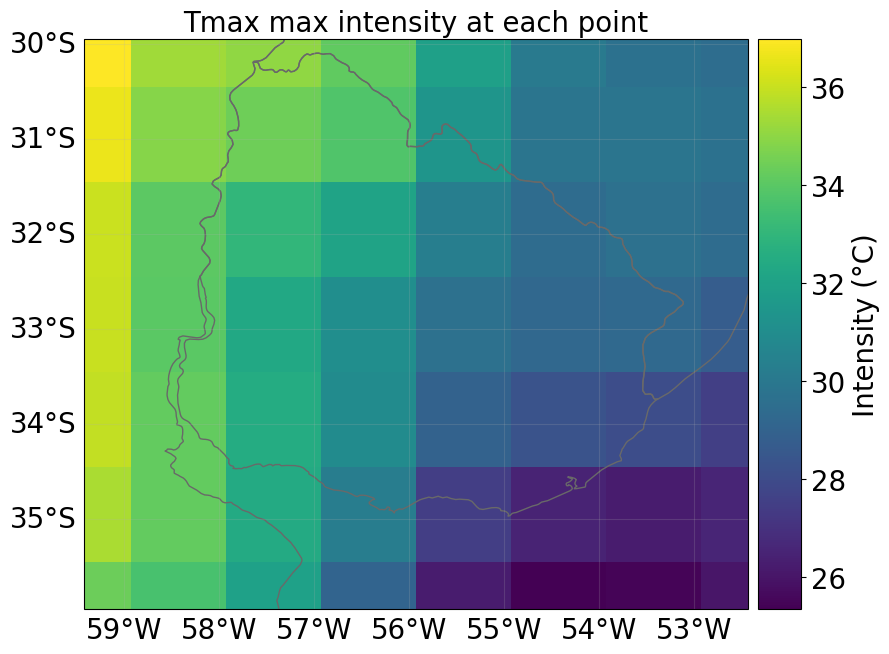
Visualizing the Calculated Hazard Object
Once the hazard object has been successfully calculated, we recoment to print the last element created is printed for visualization. This is important for several reasons:
Initial Data Inspection: The visualization allows you to view a slice of the forecast data, providing a quick check of the results. This initial glimpse helps you verify that the data processing was successful and provides insights into the distribution of the hazard (in this case, Maximum Temperature) across the area of interest.
Geographic Accuracy: The map helps you verify if the correct geographic region was processed and plotted. This is particularly useful as it allows immediate feedback on whether the user-defined boundaries or selected areas (e.g., Germany and Switzerland) were captured correctly.
Data Quality Check: Visualizing the output also serves as a preliminary quality check, allowing you to detect any unexpected results or anomalies in the data. For instance, the color bar indicating the “Intensity (days)” gives an indication of how the hazard index is distributed across the mapped area.
Quick Workflow Testing: This step is essential for testing the entire workflow, ensuring that the process is working as expected from data download, processing, and hazard object creation to visualization.
This output provides a structured dataset ready for further analysis within the CLIMADA framework, allowing for the evaluation of potential impacts and the planning of mitigation strategies.
For instance, below, we load the hazard for the last month and plot the intensity per grid point maximized over all forecast ensemble members.
from climada.hazard import Hazard
# load an example hazard
initiation_year = year_list[0]
initiation_month_str = f"{month_name_to_number(initiation_month[0]):02d}"
# Extract last valid forecast month from valid_period_str (e.g., "12_02" → 2)
forecast_month = int(forecast.valid_period_str[-2:])
forecast_year = initiation_year + 1 if int(initiation_month_str) > forecast_month else initiation_year
# Load hazard (based on INIT year)
path_to_hazard = forecast.get_pipeline_path(initiation_year, initiation_month_str, "hazard")
haz = Hazard.from_hdf5(path_to_hazard)
if haz:
available_dates = sorted(set(haz.date))
readable_dates = [dt.datetime.fromordinal(d).strftime('%Y-%m-%d') for d in available_dates]
print("Available Dates Across Members:", readable_dates)
# Look for the first day of the last forecast month
target_date = dt.datetime(forecast_year, forecast_month, 1).toordinal()
closest_date = min(available_dates, key=lambda x: abs(x - target_date))
closest_date_str = dt.datetime.fromordinal(closest_date).strftime('%Y-%m-%d')
print(f"Selected Date for Plotting: {closest_date_str}")
haz.select(date=[closest_date, closest_date]).plot_intensity(event=0, smooth=False)
else:
print("No hazard data found for the selected period.")
Available Dates Across Members: ['2022-12-01', '2023-01-01', '2023-02-01']
Selected Date for Plotting: 2023-02-01
Using the downloaded seasonal forecasts for impact and risk assessments
After specifying appropriate exposure and vulnerability information, the CLIMADA Hazard object haz can now be used to generate seasonal imapct forcasts and risk assessments. For some examples, see this google colab notebook.